Welcome to JaxMARL!








MARL but really really fast!
JaxMARL combines ease-of-use with GPU-enabled efficiency, and supports a wide range of commonly used MARL environments as well as popular baseline algorithms. Our aim is for one library that enables thorough evaluation of MARL methods across a wide range of tasks and against relevant baselines. We also introduce SMAX, a vectorised, simplified version of the popular StarCraft Multi-Agent Challenge, which removes the need to run the StarCraft II game engine.
What we provide:
- 9 MARL environments fully implemented in JAX - these span cooperative, competitive, and mixed games; discrete and continuous state and action spaces; and zero-shot and CTDE settings.
- 8 MARL algorithms, also fully implemented in JAX - these include both Q-Learning and PPO based appraoches.
Who is JaxMARL for?
Anyone doing research on or looking to use multi-agent reinforcment learning!
What is JAX?
JAX is a Python library that enables programmers to use a simple numpy-like interface to easily run programs on accelerators. Recently, doing end-to-end single-agent RL on the accelerator using JAX has shown incredible benefits. To understand the reasons for such massive speed-ups in depth, we recommend reading the PureJaxRL blog post and repository.
Basic JaxMARL API Usage
Actions, observations, rewards and done values are passed as dictionaries keyed by agent name, allowing for differing action and observation spaces. The done dictionary contains an additional "__all__" key, specifying whether the episode has ended. We follow a parallel structure, with each agent passing an action at each timestep. For asynchronous games, such as Hanabi, a dummy action is passed for agents not acting at a given timestep.
import jax
from jaxmarl import make
key = jax.random.PRNGKey(0)
key, key_reset, key_act, key_step = jax.random.split(key, 4)
# Initialise environment.
env = make('MPE_simple_world_comm_v3')
# Reset the environment.
obs, state = env.reset(key_reset)
# Sample random actions.
key_act = jax.random.split(key_act, env.num_agents)
actions = {agent: env.action_space(agent).sample(key_act[i]) for i, agent in enumerate(env.agents)}
# Perform the step transition.
obs, state, reward, done, infos = env.step(key_step, state, actions)
JaxMARL's performance
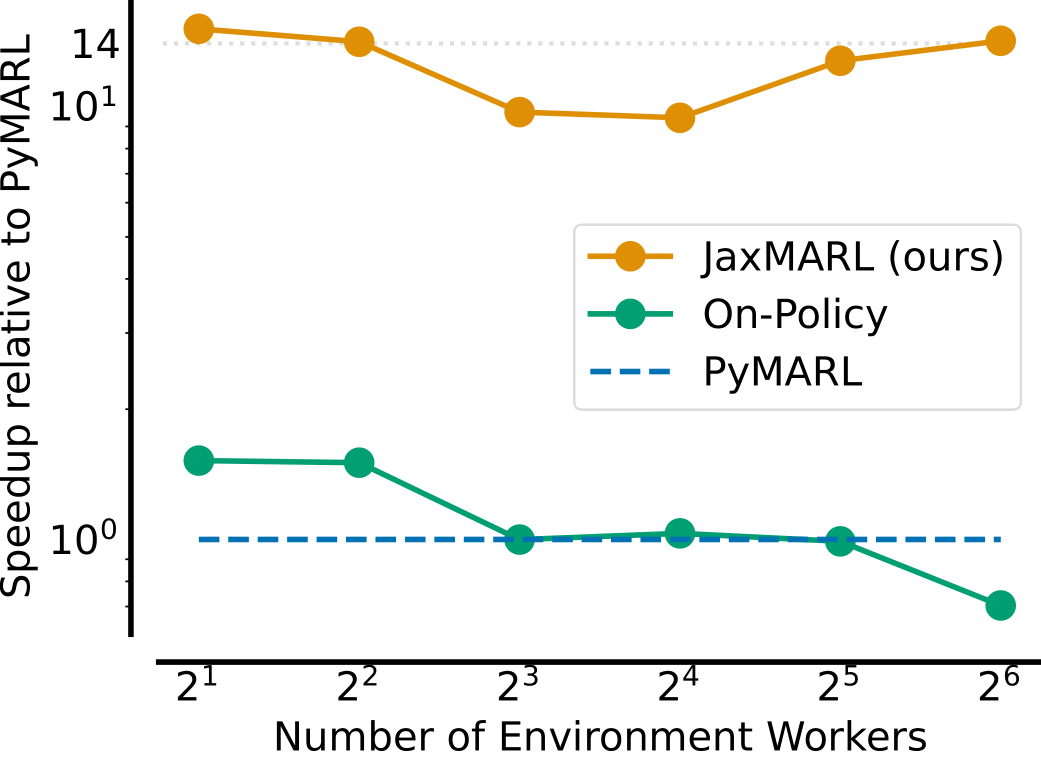
Speed of JaxMARL's training pipeline compared to two popular MARL libraries when training an RNN agent using IPPO on an MPE task.
As illustrated above, by JIT-compiling the entire traning loop JAX leads to significant training speed ups. JaxMARL is 14x faster than traditional approaches for MPE, while also producing results consistent with existing implementations. For SMAC, as SMAX does not require the StarCraft II game engine to be run, so we are over 31x faster. More results are given in our paper.
Contributing
Please contribute! Please take a look at our contributing guide for how to add an environment/algorithm or submit a bug report. If you're looking for a project, we also have a few suggestions listed under the roadmap :)
Related Works
This works is heavily related to and builds on many other works, PureJaxRL provides a list of projects within the JaxRL ecosystem. Those particularly relevant to multi-agent work are:
JAX-native algorithms:
- Mava: JAX implementations of popular MARL algorithms.
- PureJaxRL: JAX implementation of PPO, and demonstration of end-to-end JAX-based RL training.
JAX-native environments:
- Jumanji: A diverse set of environments ranging from simple games to NP-hard combinatorial problems.
- Pgx: JAX implementations of classic board games, such as Chess, Go and Shogi.
- Brax: A fully differentiable physics engine written in JAX, features continuous control tasks. We use this as the base for MABrax (as the name suggests!)
- XLand-MiniGrid: Meta-RL gridworld environments inspired by XLand and MiniGrid.
Other great JAX related works from our lab are below:
- JaxIRL: JAX implementation of algorithms for inverse reinforcement learning.
- JaxUED: JAX implementations of autocurricula baselines for RL.
- Craftax: (Crafter + NetHack) in JAX.
- Kinetix: Large-scale training of RL agents in a vast and diverse space of simulated tasks, enabled by JAX.
Other things that could help:
- Benchmarl: A collection of MARL benchmarks based on TorchRL.
Citing JaxMARL
If you use JaxMARL in your work, please cite us as follows:
@inproceedings{
flair2024jaxmarl,
title={JaxMARL: Multi-Agent RL Environments and Algorithms in JAX},
author={Alexander Rutherford and Benjamin Ellis and Matteo Gallici and Jonathan Cook and Andrei Lupu and Gar{\dh}ar Ingvarsson and Timon Willi and Ravi Hammond and Akbir Khan and Christian Schroeder de Witt and Alexandra Souly and Saptarashmi Bandyopadhyay and Mikayel Samvelyan and Minqi Jiang and Robert Tjarko Lange and Shimon Whiteson and Bruno Lacerda and Nick Hawes and Tim Rockt{\"a}schel and Chris Lu and Jakob Nicolaus Foerster},
booktitle={The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2024},
}