Switch Riddle
This directory contains an implementation of the Switch Riddle game presented in Learning to communicate with deep multi-agent reinforcement learning. Following is a prosaic description of the game:
There are n prisoners in prison and a warden. The Warden decides to free the prisoners if they can solve the following problem. So, every day the Warden will select one of the prisoners randomly and send him to an interrogation room which consists of a light bulb with a switch. If the prisoner in the room can tell that all other prisoners including him have been to the room at least once then the Warden will free all of them otherwise kill all of them. Except for the prisoner in the room, other prisoners are unaware of the fact that who got selected on that particular day to go to the interrogation room. Now, the prisoner in the interrogation room can switch on or off the bulb to send some indication to the next prisoner. He can also tell the warden that everyone has been to the room at least once or decide not to say anything. If his claim is correct, then all are set free otherwise they are all killed.
A more detailed description of the original game can be found here. The original implementation of the game is here.
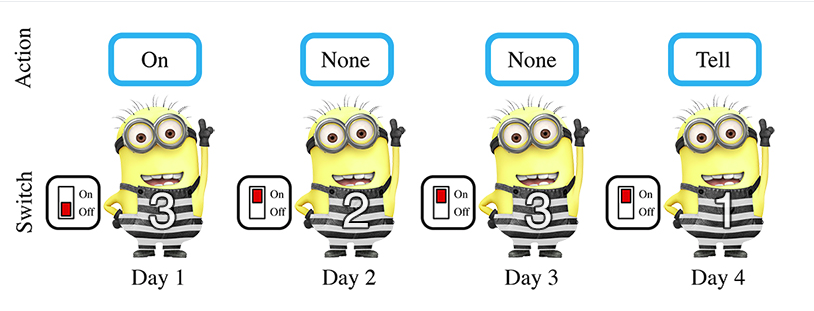
Observation, action space and reward
In this implementation, each agent receives a 2-dimensional observation vector:
| Feature Name | Value |
|---|---|
| In Room | 1 if the agent is in the room, 0 otherwise |
| Bulb State | 1 if the agent is in the room and the light is on, 0 otherwise |
The action space is different from the original one. In particular, in the original implementation each agent can *tell the warden each agent passed in the room *or **do nothing*. Next to it, it can pass a message* to the next agent (switch on-off the light). In this implementation, the message is part of the action space and the light state is embedded in the observation space.
| Action Key | Action |
|---|---|
| 0 | Do nothing |
| 1 | Switch the light (communicate) |
| 2 | Tell the warden |
The game ends when an agent tells the warden or the maximum time steps is reached. The reward is the same as in the original implementation:
- +1 if the agent in the room tells the warden and all the agents have gone to the room.
- -1 if the agent in the room tells the warden before every agent has gone to the room once.
- 0 otherwise (also if the maximum number of time steps is reached).
Usage
A pedantic snippet for verbosing the environment:
import jax
import jax.numpy as jnp
from jaxmarl import make
key = jax.random.PRNGKey(0)
env = make('switch_riddle', num_agents=5)
obs, state = env.reset(key)
for _ in range(20):
key, key_reset, key_act, key_step = jax.random.split(key, 4)
env.render(state)
print("obs:", obs)
# Sample random actions
key_act = jax.random.split(key_act, env.num_agents)
actions = {
agent: env.action_space(agent).sample(key_act[i])
for i, agent in enumerate(env.agents)
}
print(
"action:",
env.game_actions_idx[actions[env.agents[state.agent_in_room]].item()],
)
# Perform the step transition.
obs, state, reward, done, infos = env.step(key_step, state, actions)
print("reward:", reward["agent_0"])
The environment contains a rendering function that prints the current state of the environment:
>> env.render(state)
Current step: 0
Bulb state: Off
Agent in room: 0
Agents been in room: [0 0 0 0 0]
Done: False
Citation
If you use this environment, please cite:
@inproceedings{foerster2016learning,
title={Learning to communicate with deep multi-agent reinforcement learning},
author={Foerster, Jakob and Assael, Yannis M and de Freitas, Nando and Whiteson, Shimon},
booktitle={Advances in Neural Information Processing Systems},
pages={2137--2145},
year={2016}
}